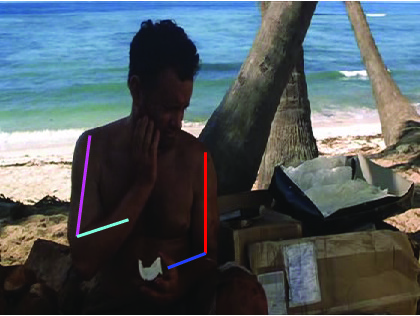
HUMAN POSE TRACKING
|
|
Human pose tracking is an important problem in computer vision due to its application in human action recognition and surveillance from video data.
Visual appearance of any human action is a sequence of various human poses. We propose that if we track those poses, then human action could be classified accurately.
In this project, we present a human pose tracking method with a new part descriptor. We formulate the human pose tracking problem as a discrete optimization problem based on spatio-temporal pictorial structure model and
solve this problem in dynamic programming framework very efficiently. We propose the model to track the human pose by combining the human pose estimation from single image
and traditional object tracking in a video. Our pose tracking objective function consists of the following
terms: likeliness of appearance of a part within a frame, temporal displacement of the part from previous frame to the current frame, and the spatial dependency of a part with its parent in the graph structure. Experimental evaluation on benchmark datasets (VideoPose2, Poses in the Wild and Outdoor Poses) as well as on our newly build ICDPose dataset shows the usefulness of our proposed method.
|
|
|
PUBLICATION
Soumitra Samanta and Bhabatosh Chanda,
A Data-driven Approach for Human Pose Tracking Based on Spatio-temporal Pictorial Structure
,
[arXiv]
[dataset]
|
|
|
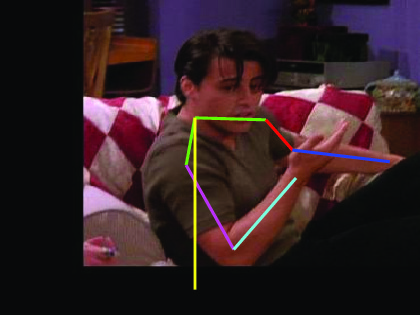
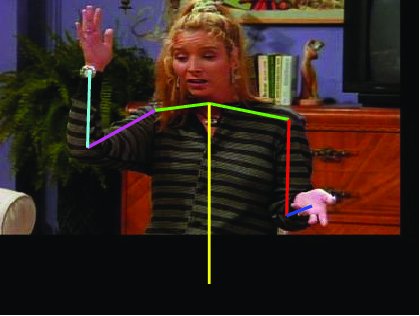
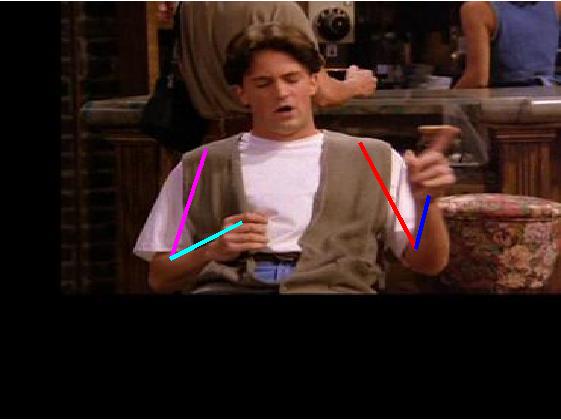
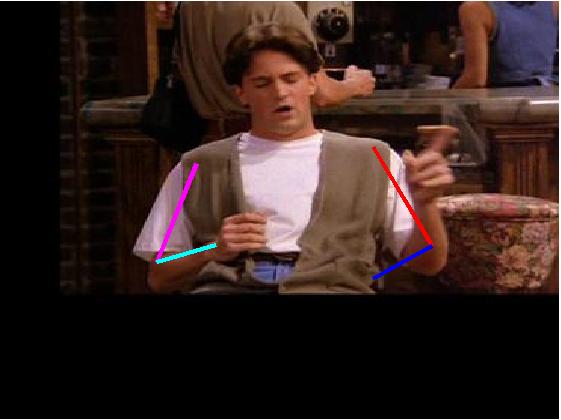
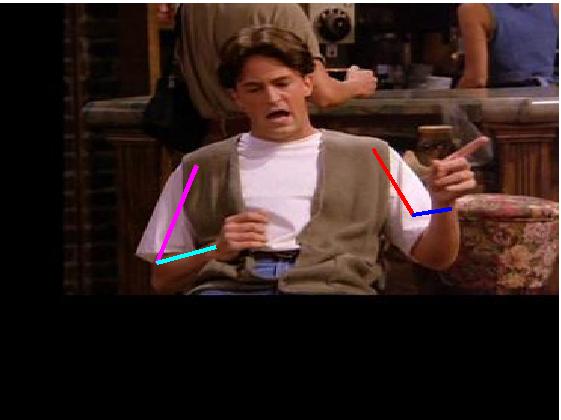
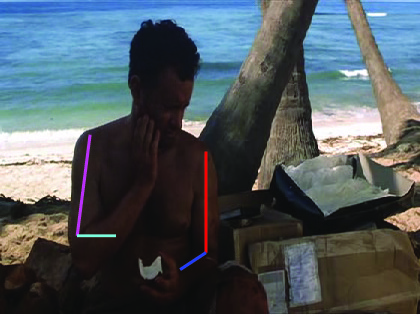
Visual comparative results of different methods on VideoPose2
dataset. Four columns indicates the four consecutive frames of a video clips
and rows indicates the different methods. First row show the ground truth part
annotation. Results using Lara et al. [37], Zhang et al. [48], Sapp et al. [35],
Park et al. [25], Cherian et al. [6] and proposed method are in 2nd, 3rd, 4th,
5th, 6th and 7th rows respectively.
|
|
|
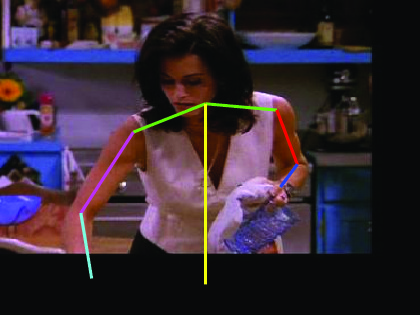
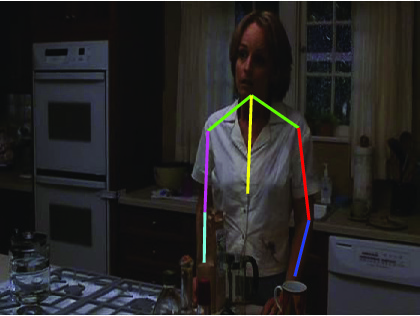
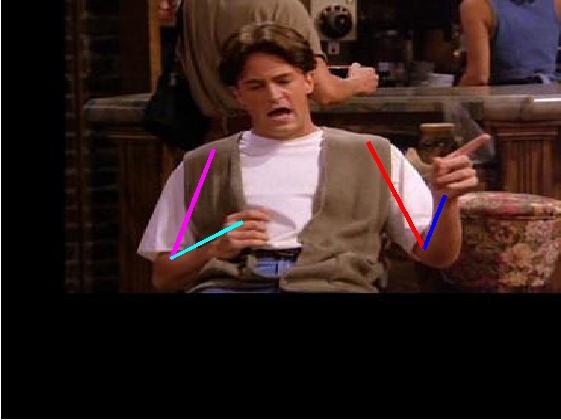
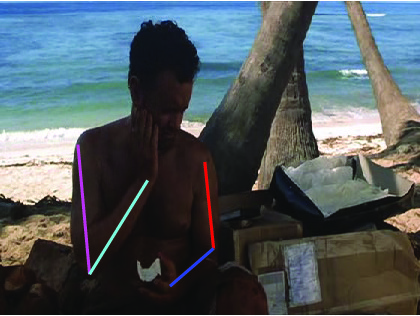
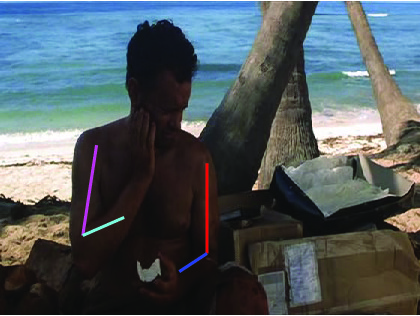
Visual comparative results of different methods on Poses in the Wild
dataset. Four columns indicates the four consecutive frames of a video clips
and rows indicates the different methods. First row show the ground truth part
annotation. Results using Lara et al. [37], Zhang et al. [48], Sapp et al. [35],
Park et al. [25], Cherian et al. [6] and proposed method are in 2nd, 3rd, 4th,
5th, 6th and 7th rows respectively.
|
|
|
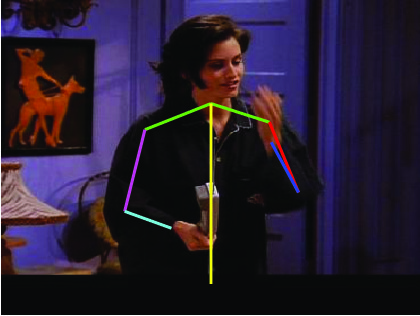
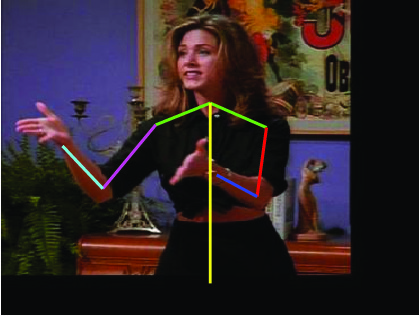
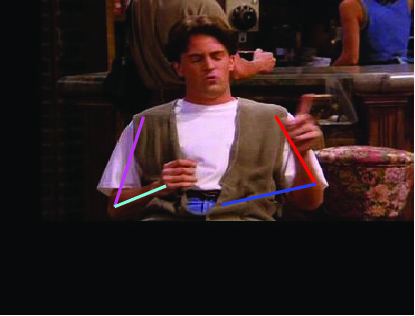
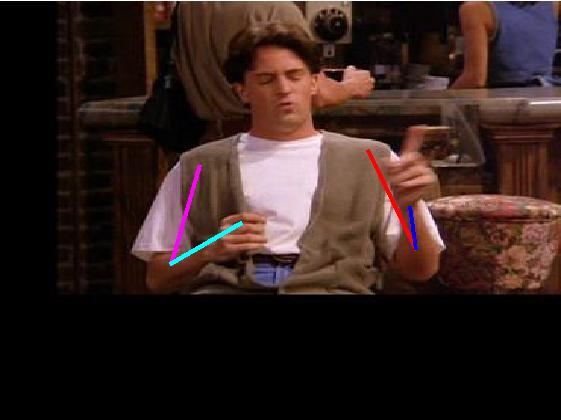
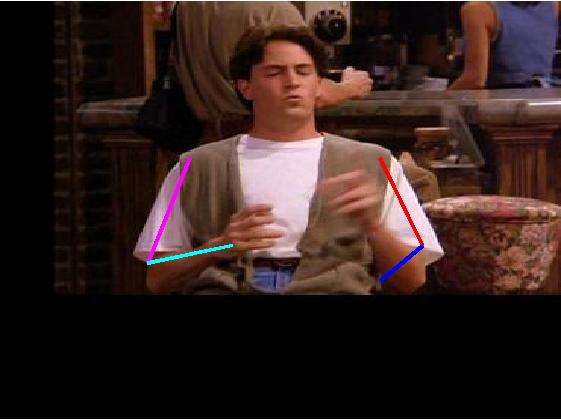
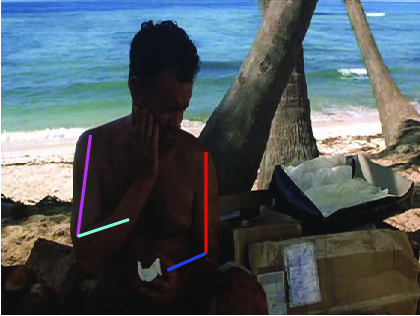
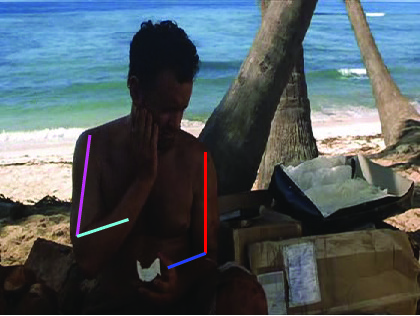
Visual results of different methods on ICDPose dataset. Four columns
indicates the four consecutive frames of a video clips. First row shows the
ground truth part annotation. Results due to Lara et al. [37], Zhang et al. [48],
Sapp et al. [35], Park et al. [25], Cherian et al. [6] and proposed method are
shown in 2nd, 3rd, 4th, 5th, 6th and 7th rows respectively.
|
|
|
RELATED PAPERS
- Laura Sevilla-Lara and Erik Learned-Miller. Distribution fields for tracking. In Proceedings of the Computer Vision and Pattern Recognition (CVPR), pages 1910-1917, June 2012.
- Kaihua Zhang, Lei Zhang, Qingshan Liu, David Zhang, and Ming-Hsuan Yang. Fast visual tracking via dense spatio-temporal context learning. In Proceedings of the European Conference on Computer Vision (ECCV), pages 127-141, September 2014.
- Dennis Park and Deva Ramanan. N-best maximal decoders for part models. In Proceedings of the International Conference on Computer Vision (ICCV), pages 2627-2634, 2011.
- Anoop Cherian, Julien Mairal, Karteek Alahari, and Cordelia Schmid.
Mixing body-part sequences for human pose estimation. In Proceedings
of the Computer Vision and Pattern Recognition (CVPR), June 2014.
- B. Sapp, D.Weiss, and B. Taskar. Parsing human motion with stretchable
models. In Proceedings
of the Computer Vision and Pattern Recognition (CVPR), June 2011.
- T. Pster, K. Simonyan, J. Charles, and A. Zisserman. Deep convolutional
neural networks for efficient pose estimation in gesture videos. In ACCV,
2014.
- Y. Yang and D. Ramanan. Articulated human detection with flexible
mixtures of parts. IEEE Trans. on PAMI, 35(12):2878-2890, 2013.
|